Usage¶
Nomenclature¶
| Keyword | Description |
|---|---|
| Future(s) | The Future class encapsulates the asynchronous execution of a callable. |
| Broker | Process dispatching Futures. |
| Worker | Process executing Futures. |
| Root | The worker executing the root Future, your main program. |
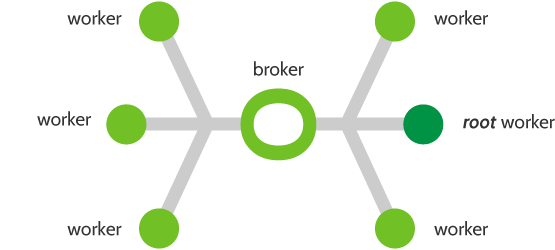
Architecture diagram¶
The future(s) distribution over workers is done by a variation of the Broker pattern. In such a pattern, workers act as independant elements that interact with a broker to mediate their communications.
Mapping API¶
The philosophy of SCOOP is loosely built around the futures module proposed
by PEP 3148. It primarily defines a map() and a
submit() function allowing asynchroneous computation that
SCOOP will propagate to its workers.
Map¶
A map() function applies multiple parameters to a single function. For example, if you want to apply the abs() function to every number of a list:
import random
data = [random.randint(-1000, 1000) for r in range(1000)]
# Without Map
result = []
for i in data:
result.append(abs(i))
# Using a Map
result = list(map(abs, data))
SCOOP’s map() returns a generator iterating over the
results in the same order as its inputs. It can thus act as a parallel
substitute to the standard map(), for instance:
# Script to be launched with: python -m scoop scriptName.py
import random
from scoop import futures
data = [random.randint(-1000, 1000) for r in range(1000)]
if __name__ == '__main__':
# Python's standard serial function
dataSerial = list(map(abs, data))
# SCOOP's parallel function
dataParallel = list(futures.map(abs, data))
assert dataSerial == dataParallel
Warning
In your root program, you must check if __name__ == '__main__' as
shown above.
Failure to do so will result in every worker trying to run their own
instance of the program. This ensures that every worker waits for
parallelized tasks spawned by the root worker.
Note
Your callable function passed to SCOOP must be picklable in its entirety.
Note that the pickle module is limited to top level functions and classes as stated in the documentation.
Note
Keep in mind that objects are not shared between workers and that changes made to an object in a function are not seen by other workers.
Map_as_completed¶
The map_as_completed() function is used exactly in the
same way as the map() function. The only difference is
that this function will yield results as soon as they are made available.
Reduction API¶
mapReduce¶
The mapReduce() function allows to parallelize a reduction
function after applying the aforementioned map() function.
It returns a single element.
A reduction function takes the map results and applies a function cumulatively
to it.
For example, applying reduce(lambda x, y: x+y, ["a", "b", "c", "d"]) would
execute (((("a")+"b")+"c")+"d") give you the result "abcd".
More information is available in the standard Python documentation on the reduce function.
A common reduction usage consist of a sum as the following example:
# Script to be launched with: python -m scoop scriptName.py
import random
import operator
from scoop import futures
data = [random.randint(-1000, 1000) for r in range(1000)]
if __name__ == '__main__':
# Python's standard serial function
serialSum = sum(map(abs, data))
# SCOOP's parallel function
parallelSum = futures.mapReduce(abs, operator.add, data)
assert serialSum == parallelSum
Note
You can pass any arbitrary reduction function, not only operator ones.
Architecture¶
SCOOP will automatically generate a binary reduction tree and submit it. Every level of the tree contain reduction nodes except for the bottom-most which contains the mapped function.

Utilities¶
Object sharing API¶
Sharing constant objects between workers is available using the
shared module.
Its functionnalities are summarised in this example:
from scoop import futures, shared
def myParallelFunc(inValue):
myValue = shared.getConst('myValue')
return inValue + myValue
if __name__ == '__main__':
shared.setConst(myValue=5)
print(list(futures.map(myParallelFunc, range(10))))
Note
A constant can only be defined once on the entire pool of workers. More information in the Shared module reference.
Logging¶
You can use the scoop.logger to output useful information alongside your log messages such as the time, the worker name which emitted the message and the module in which the message was emitted.
Here is a sample usage:
import scoop
scoop.logger.warn("This is a warning!")
How to launch SCOOP programs¶
Programs using SCOOP, such as the ones in the examples/ directory,
need to be launched with the -m scoop parameter passed to Python, as
such:
cd scoop/examples/
python -m scoop fullTree.py
Note
When using a Python version prior to 2.7, you must start SCOOP using -m scoop.__main__ .
You should also consider using an up-to-date version of Python.
Launch in details¶
The SCOOP module spawns the needed broker(s) and worker(s) on the given list of computers, including remote ones via ssh.
Every worker imports your program with a __name__ variable different than __main__ then awaits orders given by the root node to execute available functions. This is necessary to have references over your functions and variables in the global scope.
This means that everything (definitions, assignments, operations, etc.) in the global scope of your program will be executed by every worker. To ensure a section of your code is only executed once, you must place a conditional barrier such as this one:
if __name__ == '__main__':
An example with remote workers may be as follow:
python -m scoop --hostfile hosts -vv -n 6 your_program.py [your arguments]
| Argument | Meaning |
|---|---|
| -m scoop | Mandatory Uses SCOOP to run program. |
| –hostfile | hosts is a file containing a list of host to launch SCOOP |
| -vv | Double verbosity flag. |
| -n 6 | Launch a total of 6 workers. |
| your_program.py | The program to be launched. |
| [your arguments] | The arguments that needs to be passed to your program. |
Note
Your local hostname must be externally routable for remote hosts to be able to connect to it. If you don’t have a DNS properly set up on your local network or a system hosts file, consider using the --broker-hostname argument to provide your externally routable IP or DNS name to SCOOP. You may as well be interested in the -e argument for testing purposes.
Hostfile format¶
You can specify the hosts with a hostfile and pass it to SCOOP using the --hostfile argument.
The hostfile should use the following syntax:
hostname_or_ip 4
other_hostname
third_hostname 2
The name being the system hostname and the number being the number of workers to launch on this host. The number of workers to launch is optional. If omitted, SCOOP will launch as many workers as there are cores on the machine.
Using a list of host¶
You can also use a list of host with the --host [...] flag. In this
case, you must put every host separated by a space the number of time you wish
to have a worker on each of the node. For example:
python -m scoop --host machine_a machine_a machine_b machine_b your_program.py
This example would start two workers on machine_a and two workers on machine_b.
Choosing the number of workers¶
The number of workers started should be equal to the number of cores you have
on each machine. If you wish to start more or less workers than specified in your
hostfile or in your hostlist, you can use the -n parameter.
Be aware that tinkering with this parameter may hinder performances.
Note
The -n parameter overrides any previously specified worker
amount.
If -n is less than the sum of workers specified in the hostfile
or hostlist, the workers are launched in batch by host until the parameter
is reached. This behavior may ignore latters hosts.
If -n is more than the sum of workers specified in the hostfile
or hostlist, the remaining workers are distributed using a Round-Robin
algorithm. Each host will increment its worker amount until the parameter
is reached.
Use with a scheduler¶
You must provide a startup script on systems using a scheduler such as
supercomputers or laboratory grids. Here are some example startup scripts
using different grid task managers. Some example startup scripts are available
in the examples/submit_files directory.
SCOOP natively supports Sun Grid Engine (SGE), Torque (PBS-compatible, Moab, Maui) and SLURM. That means that a minimum launch file is needed while the framework recognizes automatically the nodes assigned to your task.
Note
These are only examples. Refer to the documentation of your scheduler for the list of arguments needed to run the task on your grid or cluster.
Use on cloud services¶
Pitfalls¶
Program scope¶
As a good Python practice (see PEP 395#what-s-in-a-name), you should always wrap the executable part of your program using:
if __name__ == '__main__':
This is mandatory when using parallel frameworks such as multiprocessing or SCOOP. For an explanation why, read the Launch in details section.
If your program lacks this conditional barrier, your whole program will be executed as many times as there are workers, meaning duplicate work is being done.
Unpicklable Future¶
Only functions or classes declared at the top level of your program are picklables. This is a limitation of Python’s pickle module. Here are some examples of non-working map invocations:
from scoop import futures
class myClass(object):
@staticmethod
def myFunction(x):
return x
if __name__ == '__main__':
def mySecondFunction(x):
return x
# Both of these calls won't work because Python pickle won't be able to
# pickle or unpickle the function references.
wrongCall1 = futures.map(myClass.myFunction, [1, 2, 3, 4, 5])
wrongCall2 = futures.map(mySecondFunction, [1, 2, 3, 4, 5])
Launching a faulty program will result in this error being displayed:
[...] This element could not be pickled: [...]
Mutable arguments¶
In standard programs, modifying a mutable function argument also modifies it in the caller scope because objects are passed by reference. This side-effect is not simulated in SCOOP. Function arguments are not serialized back along its answer.
Lazy-like evaluation¶
The map() and submit() will
distribute their Futures both locally and remotely. Futures executed locally
will be computed upon access (iteration for the map()
and result() for submit()).
Futures distributed remotely will be executed right away.
Large datasets¶
Every parameter sent to a function by a map() or
submit() gets serialized and sent within the Future to
its worker. Sending large elements as parameter(s) to your function(s) results
in slow speeds and network overload.
You should consider using a global variable in your module scope for passing large elements. It will then be loaded on launch by every worker and won’t overload your network.
Unefficient:
from scoop import futures
def mySum(inData):
"""The worker will receive all its data from network."""
return sum(inData)
if __name__ == '__main__':
data = [[i for i in range(x, x + 1000)] for x in range(0, 8001, 1000)]
results = list(futures.map(mySum, data))
Better efficiency:
from scoop import futures
data = [[i for i in range(x, x + 1000)] for x in range(0, 8001, 1000)]
def mySum(inIndex):
"""The worker will only receive an index from network."""
return sum(data[inIndex])
if __name__ == '__main__':
results = list(futures.map(mySum, range(len(data))))
SCOOP and greenlets¶
Warning
Since SCOOP uses greenlets to schedule and run futures, programs that use their own greenlets won’t work with SCOOP. However, you should consider replacing the greenlets in your code by SCOOP functions.